URI, URL, URN
URI, URL, URN?
- URI : Uniform Resource Identifier (통합 자원 식별자)
- URL : Uniform Resource Location
- URN : Uniform Resource Name
1) URI
통합 자원 식별자(Uniform Resource Identifier, URI)는 인터넷에 있는 자원을 나타내는 유일한 주소이다. URI의 존재는 인터넷에서 요구되는 기본조건으로서 인터넷 프로토콜에 항상 붙어 다닌다.
URI의 하위개념으로 URL, URN 이 있다.
- 위키백과 (통합 자원 식별자)
A Uniform Resource Identifier (URI) is a unique sequence of characters that identifies a logical or physical resource used by web technologies.
- Wikipedia (Uniform Resource Identifier)
URI란 인터넷에 있는 자원(파일, 데이터, 웹 페이지 등) 각각을 가리키는 고유한 값이다.
URI가 어떤 자원의 위치(주소)를 담고 있으면 URL이라 하고, 위치가 아닌 고유한 이름을 담고 있으면 URN이라 한다.
예를 들어 정부 기관에서 나를 찾아오려고 할 때, 내 집 주소를 통해 찾아 오거나 내 이름과 주민등록번호를 통해 찾아올 수도 있다.
여기서 내 집 주소가 URL이고, 내 이름과 주민등록번호의 조합이 URN이라고 할 수 있다.

URI 표기 방식은 아래와 같다.
URI = scheme ":" ["//" authority] path ["?" query] ["#" fragment]
authority = [userinfo "@"] host [":" port]
userinfo host port
┌──┴───┐ ┌──────┴──────┐ ┌┴┐
https://john.doe@www.example.com:123/forum/questions/?tag=networking&order=newest#top
└─┬─┘ └───────────┬──────────────┘└───────┬───────┘ └───────────┬─────────────┘ └┬┘
scheme authority path query fragment
ldap://[2001:db8::7]/c=GB?objectClass?one
└┬─┘ └─────┬─────┘└─┬─┘ └──────┬──────┘
scheme authority path query
mailto:John.Doe@example.com
└─┬──┘ └────┬─────────────┘
scheme path
news:comp.infosystems.www.servers.unix
└┬─┘ └─────────────┬─────────────────┘
scheme path
tel:+1-816-555-1212
└┬┘ └──────┬──────┘
scheme path
telnet://192.0.2.16:80/
└─┬──┘ └─────┬─────┘│
scheme authority path
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
└┬┘ └──────────────────────┬──────────────────────┘
scheme path2) URL
URL(Uniform Resource Locator 또는 web address, 문화어: 파일식별자, 유일자원지시기)은 네트워크 상에서 자원이 어디 있는지를 알려주기 위한 규약이다.
즉, 컴퓨터 네트워크와 검색 메커니즘에서의 위치를 지정하는, 웹 리소스에 대한 참조이다.쉽게 말해서, 웹 페이지를 찾기위한 주소를 말한다.
- 위키백과 (URL)
위에서 URL은 어떤 자원의 위치(주소)를 나타낸다고 하였다.
집 주소도 규칙을 갖고서 정해지듯이, URL도 규칙이 있다.
scheme://<user>:<password>@<host>:<port>/<url-path>아래는 위의 표현보다는 친숙할 만한 HTTP URL의 표현 방식이다.
http://<host>:<port>/<path>?<searchpart>뭐가 어떻게 되는건지 언뜻 봐서는 여전히 잘 모르겠다. 아래 예시를 보자.
https://www.google.com:443/search?q=URL- https:// -> URL의 맨 앞 부분으로, 프로토콜 이름이 들어간다.
이는 접근하려는 자원에 어떤 방식으로 접근할 것인지를 나타낸다. - www.google.com -> 프로토콜 다음으로 도메인 이름 또는 IP 주소가 나온다.
www.google.com 대신에 172.217.175.228을 입력해도 위의 URL과 동일한 결과를 얻을 수 있다. - :443 -> 도메인 이름 또는 IP 주소 뒤에는 포트(Port) 번호가 나온다.
이는 해당 도메인으로 접근하되, 어느 문으로 들어갈 것인지 정해주는 것과 같다. - /search -> 이는 접근하려는 자원이 있는 디렉토리 경로를 나타낸다.
자원이 이미지나 파일인 경우 경로 마지막에 .jpg나 .csv 같은 파일 확장자가 붙어 있을 것이다. 웹 페이지는 .html, .jsp 등이 표시되기도 하는데, 웹 프레임워크 등의 사용으로 이러한 확장자 표시가 생략될 수도 있다. - ?q=URL -> 이는 쿼리(query)로서 가져오려는 자원에 대하여 특정한 조건을 걸어서 가져오기 위한 것이다.
예시의 경우에는 q의 값이 'URL'인 자원을 요청한다는 의미이다.
위에서 사용했던 정부 기관이 나에게 찾아 오는 상황에 비유하자면,
(1) 먼저 정부 기관에서 우리 집에 무슨 목적으로 찾아올지 정해진다(프로토콜. http, ftp 등).
(2) 그리고 집 주소가 어떻게 되는지 건물명이나 지번 주소 등으로 명확히 정한다(도메인 이름 or IP 주소).
(3) 그 다음 현관문으로 들어올지, 베란다 창문으로 들어올지, 배관으로 침투할지 정한다(포트 선택. 80, 443, 3306 등).
(4) 그런 후에 구체적으로 집 내부 어디로 접근 및 침투를 할지 경로 설정을 한다(디렉토리 경로. ex. /거실/안방/침대밑).
(5) 마지막으로 어떤 조건을 기준으로 누구를 데려갈지 결정한다(쿼리. ?성별=남성&키=180).
3) URN
URN(Uniform Resource Name, 통합 자원 이름)은 urn:scheme 을 사용하는 URI를 위한 역사적인 이름이다. URN은 영속적이고, 위치에 독립적인 자원을 위한 지시자로 사용하기 위해 1997년도 RFC 2141 문서에서 정의되었다.
- 위키백과 (URN)
A Uniform Resource Name (URN) is a Uniform Resource Identifier (URI) that uses the urn scheme.
URNs are globally unique persistent identifiers assigned within defined namespaces so they will be available for a long period of time, even after the resource which they identify ceases to exist or becomes unavailable.
URNs cannot be used to directly locate an item and need not be resolvable, as they are simply templates that another parser may use to find an item.- Wikipedia (Uniform Resource Name)
정부에서 우리 집을 급습하여 나를 데려가려고 했다. 그러나 내가 집에 없었다면?
날 데려가려는 정부의 작전은 실패한 것이다. 따라서 정부는 나를 추적할 다른 방법을 쓰기로 했다.
그들은 내 이름과 주민등록번호로 나를 추적했고, 결국 나는 그들에게 잡혔다.
URL은 어떤 자원의 위치를 의미할 뿐, 그 자체가 해당 자원을 가리키는 것은 아니다.
그러므로 이 자원의 위치가 바뀐 후에 동일한 URL로 접근하면 해당 자원을 찾을 수 없다.
이런 이유로 자원의 위치가 이곳 저곳으로 바뀌어도 이를 찾을 수 있는 방법이 필요했고, 그 결과 URN이 나왔다.
URN의 표기 방식은 아래와 같다.
<URN> ::= "urn:" <NID> ":" <NSS>- NID : Namespace IDentifier. URN으로 지정할 자원의 분류를 나타낸다.
- NSS : Namespace Specific String. NID 내에서 해당 자원이 갖는 고유값이다.
만약 나를 URN으로 표현한다면 urn:republicofkorea:************* 이런 식으로 표현할 수 있을 것이다(별표는 주민등록번호가 들어간다고 생각해주세요. 이해를 돕기 위한 예시일 뿐, 실제로 이렇게 표현되는 것은 아닙니다!).
인터넷에서 도서를 찾다가 보면 ISBN이라는 글자와 함께 그 옆에 숫자가 길게 써있는 것을 볼 수 있는데, 이것이 URN이다(참고로 ISBN은 International Standard Book Number, '국제표준도서번호'이다).
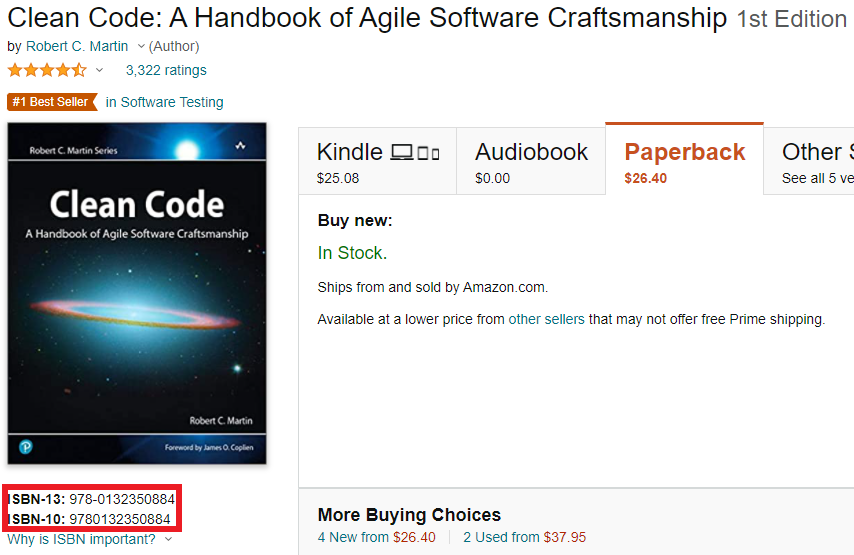
위 도서를 URN으로 표현하면 urn:isbn:9780132350884 이다.