데이터베이스 언어 (Database Language)
데이터베이스 언어란?
데이터베이스 언어(영어: Database Language)는 컴퓨터의 데이터베이스 작업을 위한 컴퓨터 언어이다. 데이터베이스 언어를 사용하여 데이터베이스 사용자 및 응용 프로그램 소프트웨어는 데이터베이스에 액세스 할 수 있다. 데이터베이스를 취급하는 기능 중 검색(질의)가 중요하기 때문에, 통례는 (데이터베이스) 쿼리 언어라고도 불린다. 그러나 데이터베이스 언어 및 질의 언어는 개념적으로 겹치는 부분도 있지만, 동의어는 아니다.
2008년 현재 가장 대중적 데이터베이스 언어는 관계 데이터베이스의 데이터베이스 언어 SQL이다.
- 위키백과 (데이터베이스 언어)
데이터베이스 언어란 데이터베이스를 다루기 위한 명령어의 모음이라고 할 수 있다.
데이터베이스를 어떠한 목적을 갖고서 다루는가에 따라서 데이터 정의 언어(DDL), 데이터 조작 언어(DML), 데이터 제어 언어(DCL) 그리고 트랜잭션 제어 언어(TCL)로 구분한다.
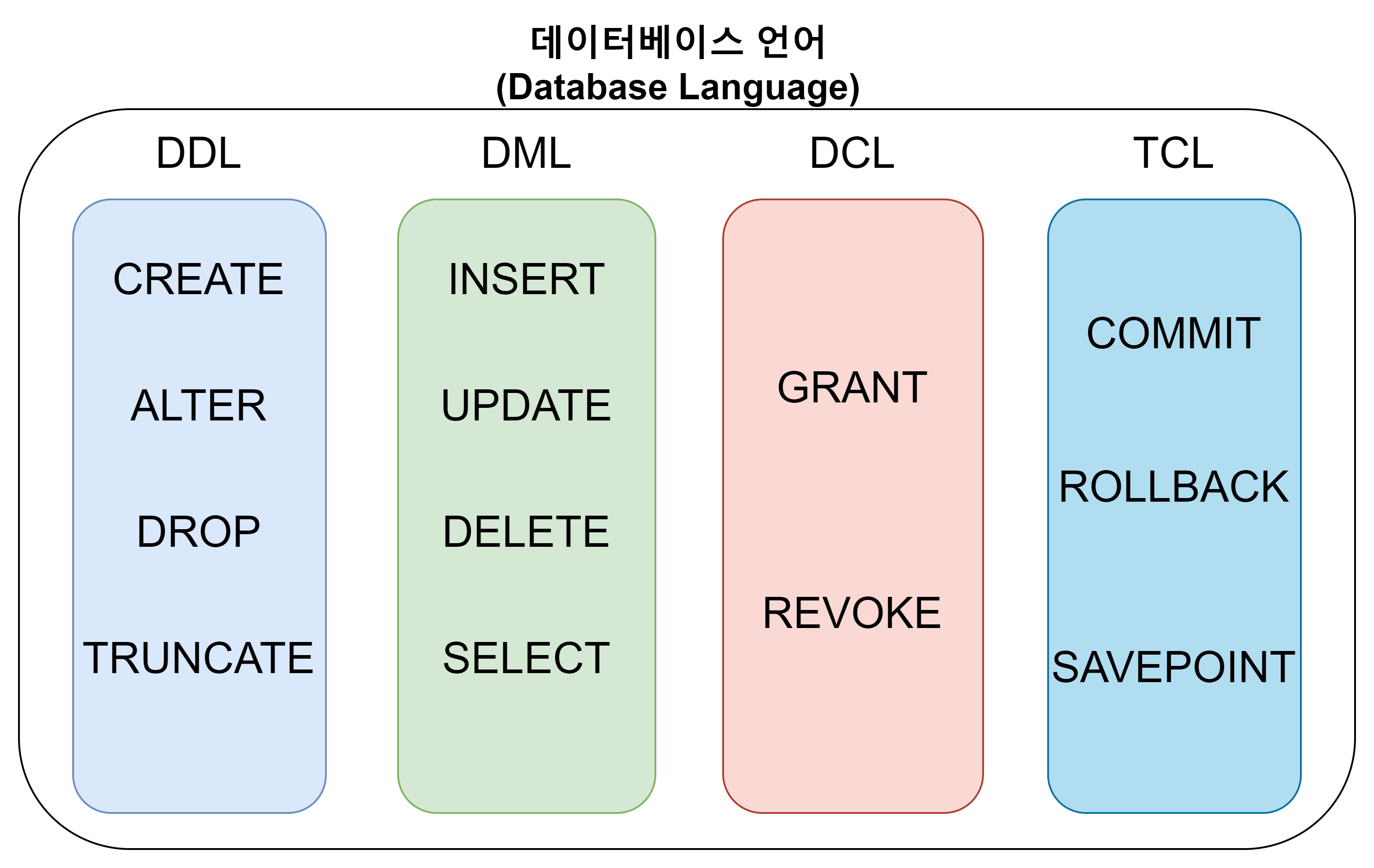
1) 데이터 정의 언어 (DDL; Data Definition Language)
데이터 정의 언어(영어: data definition language, DDL)는 컴퓨터 사용자 또는 응용 프로그램 소프트웨어가 컴퓨터의 데이터를 정의하는 컴퓨터 언어 또는 컴퓨터 언어 요소이다. ...(중략)...
SQL의 데이터 정의 언어의 문장은 관계형 데이터베이스의 구조를 정의한다. SQL에 의해 정의되는 관계형 데이터베이스의 구조는 쌍(행), 속성(열), 관계(테이블), 인덱스 파일 위치 등 데이터베이스 고유의 특성을 포함한다.
- 위키백과 (데이터 정의 언어)
데이터 정의 언어는 데이터베이스의 구조, 즉 테이블을 다루기 위한 명령어들이다.
데이터 정의 언어에는 CREATE, ALTER, DROP, TRUNCATE가 있다.
- CREATE
- 새로운 테이블을 생성하기 위한 명령어
CREATE TABLE Employee (
id INTEGER PRIMARY KEY,
last_name VARCHAR(75) NOT NULL,
first_name VARCHAR(50) NULL,
date_of_birth DATE NULL
);- ALTER
- 주로 기존에 존재하는 테이블의 컬럼 정보를 변경하기 위한 명령어
- 테이블명 변경도 가능
-- 컬럼 추가
ALTER TABLE Employee ADD address TEXT;
-- 컬럼 추가 (특정 컬럼 뒤에 위치하기)
ALTER TABLE Employee ADD COLUMN mid_name VARCHAR(32) DEFAULT NULL AFTER last_name;
-- 컬럼 설정 변경
ALTER TABLE Employee MODIFY COLUMN first_name CHAR(55) NOT NULL;
-- 컬럼명 및 설정 동시에 변경 (컬럼명만 변경 가능)
ALTER TABLE Employee CHANGE COLUMN first_name 1st_name VARCHAR(32) NULL;
-- 컬럼 제거
ALTER TABLE Employee DROP COLUMN address;
-- 테이블명 변경
ALTER TABLE Employee RENAME TO Employee_new;- DROP
- 데이터베이스 또는 테이블을 삭제하기 위한 명령어
-- 테이블 제거
DROP TABLE Employee_new;
-- 데이터베이스 제거
DROP DATABASE Company;- TRUNCATE
- 테이블 자체가 아닌 테이블 내부에 있는 레코드 전체를 삭제하기 위한 명령어
TRUNCATE TABLE Employee;2) 데이터 조작 언어 (DML; Data Manipulation Language)
데이터 조작 언어(영어: Data Manipulation Language, DML)은 데이터베이스 사용자 또는 응용 프로그램 소프트웨어가 컴퓨터 데이터베이스에 대해 데이터 검색, 등록, 삭제, 갱신을 위한 데이터베이스 언어 또는 데이터베이스 언어 요소이다.
2007년 현재 가장 대중적 데이터 조작 언어는 SQL 데이터 조작 언어이다. SQL은 관계형 데이터베이스에 대해 검색 및 업데이트 등의 데이터 조작을 위해 사용된다.
- 위키백과 (데이터 조작 언어)
데이터 조작 언어는 테이블 내에 저장되는 데이터를 관리하기 위한 명령어들이다.
데이터 조작 언어에는 INSERT, UPDATE, DELETE, SELECT가 있다.
- INSERT
- 테이블에 데이터를 입력하기 위한 명령어
INSERT INTO Employee (id, last_name, first_name, date_of_birth) VALUES (1, 'Doe', 'John', DATE_FORMAT(NOW(), '%Y-%m-%d'));- UPDATE
- 테이블 내 데이터를 수정하기 위한 명령어
- 수정하려는 테이블과 컬럼, 그리고 수정되는 값을 넣음
- WHERE 등의 조건을 이용하여 특정 레코드의 값만 수정 가능
UPDATE Employee SET first_name = 'updated';
-- WHERE 조건 추가
UPDATE Employee SET first_name = 'Mike' WHERE id = 2;- DELETE
- 테이블 내 레코드를 삭제하기 위한 명령어
- WHERE 등의 조건이 없으면 전체 레코드가 삭제됨
- DDL 중 TRUNCATE와의 차이점으로, TRUNCATE는 명령어를 실행하면 작업이 자동으로 확정(AUTO COMMIT)이 되나, DELETE는 작업을 취소(ROLLBACK) 가능
-- 전체 레코드 삭제
DELETE FROM Employee;
-- WHERE 조건을 추가하여 일부 레코드만 삭제
DELETE FROM Employee WHERE id = 2;- SELECT
- 테이블에 저장된 데이터를 조회하기 위한 명령어
- SELECT 뒤에 조회하려는 컬럼명을 입력하여 특정 컬럼만 조회 가능(전체 컬럼 조회는 애스터리스크(*)를 입력)
- 컬럼명 입력 시 AS 키워드를 통해 별명(Alias)을 부여하여 출력되는 컬럼명 변경 가능
- WHERE, GROUP BY, JOIN 등의 조건을 이용하여 원하는 데이터 조회 가능
-- 아무 조건이 없으므로 테이블 내 모든 레코드를 조회
SELECT * FROM Employee;
-- WHERE 조건을 통해 특정 레코드만 조회
SELECT * FROM Employee WHERE id = 1;
-- last_name 컬럼의 별명을 LN으로 지정
-- 데이터 조회 시 last_name의 컬럼명이 LN으로 출력됨
SELECT last_name AS LN FROM Employee;3) 데이터 제어 언어 (DCL; Data Control Language)
데이터 제어 언어(영어: Data Control Language, DCL)는 데이터베이스에서 데이터에 대한 액세스를 제어하기 위한 데이터베이스 언어 또는 데이터베이스 언어 요소이다.
권한 부여(GRANT)와 박탈(REVOKE)이 있으며, 설정할 수 있는 권한으로는 연결(CONNECT), 질의(SELECT), 자료 삽입(INSERT), 갱신(UPDATE), 삭제(DELETE) 등이 있다.- 위키백과 (데이터 제어 언어)
데이터 제어 언어는 데이터베이스의 유저를 생성하고 권한을 제어하기 위한 명령어들이다.
주요 데이터 제어 언어에는 GRANT, REVOKE가 있다.
데이터 제어 언어로 설정 가능한 권한으로는 아래와 같은 것들이 있다.
- CONNECT : 데이터베이스에 연결할 수 있는 권한
- SELECT : 데이터베이스의 데이터를 조회할 수 있는 권한
- INSERT : 데이터베이스의 데이터를 등록할 수 있는 권한
- UPDATE : 데이터베이스의 데이터를 수정할 수 있는 권한
- DELETE : 데이터베이스의 데이터를 삭제할 수 있는 권한
- GRANT
- 특정한 데이터베이스 유저에게 어떠한 작업을 수행할 권한을 부여하는 명령어
- 모든 권한을 부여하려면 ALL PRIVILEGES를 권한 자리에 입력
- 특정 테이블이 아닌 모든 테이블에 대해 권한을 부여하려면 애스터리스크(*)를 테이블명 자리에 입력(모든 DB, 모든 테이블이라면 둘 다 애스터리스크 입력)
GRANT SELECT,INSERT,UPDATE,DELETE ON Company.Employee TO User1;
-- Company 데이터베이스의 모든 테이블에 대하여 모든 권한 부여
GRANT ALL PRIVILEGES ON Company.* TO User1;- REVOKE
- 특정한 데이터베이스 유저에게 부여되어 있던 특정 권한을 박탈하는 명령어
- 모든 권한을 박탈하려면 권한 자리에 ALL을 입력
REVOKE INSERT ON Company.Employee FROM User1;
-- 모든 권한 박탈하기
REVOKE ALL ON Company.Employee FROM User1;4) 트랜잭션 제어 언어 (TCL; Transaction Control Language)
Transaction Control Language commands are used to manage transactions in the database. These are used to manage the changes made by DML-statements. It also allows statements to be grouped together into logical transactions.
- GeeksforGeeks (SQL | DDL, DML, TCL and DCL)
트랜잭션 제어 언어란 트랜잭션을 조작하기 위한 명령어들이다.
트랜잭션 제어 언어에는 COMMIT, ROLLBACK, SAVEPOINT가 있다.
트랜잭션 제어 언어를 사용하기 위해서는 먼저 트랜잭션을 시작(START TRANSACTION)해야 한다.
(트랜잭션에 대해 보다 자세한 설명을 원하시면 [DB] 데이터베이스 트랜잭션(Database Transaction) 참고 바랍니다!)
- COMMIT
- 트랜잭션 수행 결과를 확정하기 위한 명령어
START TRANSACTION; -- 트랜잭션 시작
INSERT INTO Employee (id, last_name, first_name, date_of_birth) VALUES (3, 'Blue', 'Coral', DATE_FORMAT(NOW(), '%Y-%m-%d'));
UPDATE Employee SET first_name = 'Mike' WHERE id = 3;
COMMIT; -- 이후 데이터를 조회하면 추가된 데이터를 확인할 수 있다- ROLLBACK
- 트랜잭션 수행 결과를 취소하기 위한 명령어
- 트랜잭션이 ROLLBACK으로 끝나면 데이터베이스는 트랜잭션이 시작되기 이전 상태로 되돌아감
START TRANSACTION; -- 트랜잭션 시작
INSERT INTO Employee (id, last_name, first_name, date_of_birth) VALUES (4, 'Red', 'Strong', DATE_FORMAT(NOW(), '%Y-%m-%d'));
UPDATE Employee SET first_name = 'Mike' WHERE id = 4;
ROLLBACK; -- 이후 데이터를 조회 시 트랜잭션 시작 이전 상태로 되돌아간 것을 확인할 수 있다- SAVEPOINT
- 트랜잭션 수행 결과의 일부는 남겨 두고, 일부는 취소하려는 등의 경우에 사용하는 명령어
- ROLLBACK TO [SAVEPOINT 명칭] 명령어를 통해서 사용됨
- SAVEPOINT 이전 지점까지의 트랜잭션 수행 결과는 남기고, 이후의 수행 결과는 ROLLBACK됨
START TRANSACTION; -- 트랜잭션 시작
INSERT INTO Employee (id, last_name, first_name, date_of_birth) VALUES (5, 'America', 'Captain', DATE_FORMAT(NOW(), '%Y-%m-%d'));
SAVEPOINT SVPT1; -- SAVEPOINT 지정
INSERT INTO Employee (id, last_name, first_name, date_of_birth) VALUES (6, 'Beans', 'Chris', DATE_FORMAT(NOW(), '%Y-%m-%d'));
ROLLBACK TO SVPT1; -- 이후 데이터를 조회 시 Captain America는 남아 있고 Chris Beans는 없어진 것을 확인할 수 있다<참고 자료>
- 데이터베이스 언어 - 위키백과
- 데이터 정의 언어 - 위키백과
- 데이터 조작 언어 - 위키백과
- 데이터 제어 언어 - 위키백과
- SQL - 위키백과
- DDL - 데이터온에어
- DML - 데이터온에어
- DCL - 데이터온에어
- TCL - 데이터온에어
- SQL Commands: DML, DDL, DCL, TCL, DQL with Query Example - Guru99
- SQL | DDL, DML, TCL and DCL - GeeksforGeeks
- DBMS languages - BeginnersBook
- Transaction Control Language - EDUCBA
- Database Language - javapoint
- Types of Database Languages and Their Uses (Plus Examples) - Indeed Editorial Team
- Are DDL commands Autocommit?
- Are dcl commands autocommit?
- [MySQL || MariaDB] ALTER TABLE 문법 총 정리 - .java의 개발일기
- Mysql/Mariadb 권한 확인 (grant / revoke) - 화곡공룡의 일상다반사
- mysql 사용자추가/DB생성/권한부여 - nickjoIT
'Database > Knowledge' 카테고리의 다른 글
| [DB] 데이터베이스 스키마(Database Schema) (feat. 데이터베이스 사상(Database Mapping)) (0) | 2021.11.24 |
|---|---|
| [DB] 데이터베이스 정규화(Database Normalization) (0) | 2021.11.21 |
| [DB] 데이터베이스 트랜잭션(Database Transaction) (0) | 2021.11.21 |
| [DB] 데이터베이스 관계(Database Relationships) (0) | 2021.11.18 |




















