기준 모델(Baseline Model)
기준 모델이 뭐지?
baseline
an imaginary line used as a starting point for making comparisons
- Cambridge English Dictionarya line serving as a basis
- Merriam-Webster
AI : 사장님. 저 일. 다했습니다. 저 잘했습니다. 삐릿삐릿.
사장 : 너는 뭘 믿고 너가 잘했다고 생각하니?
AI : 제가. '저 친구'보다는. 잘했습니다. 삐릿삐릿.
- 작자 미상 (사실은 블로그 작성자 머릿속...)
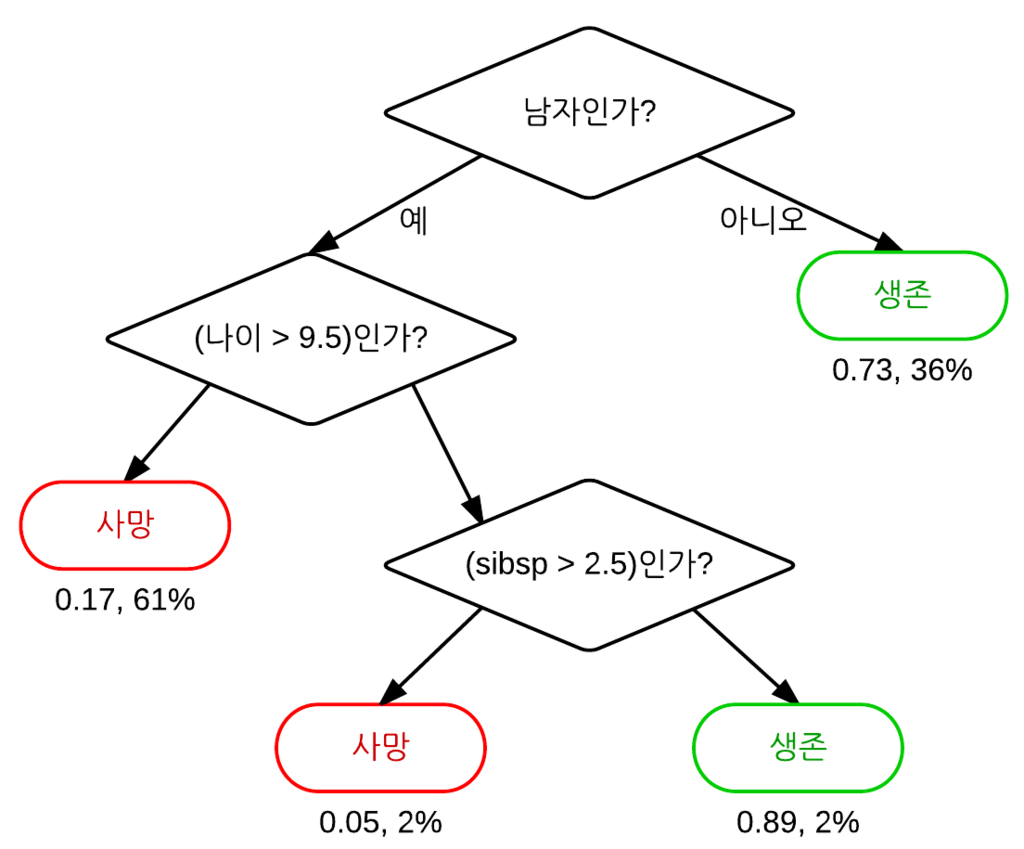
기준 모델은 머신 러닝 모델을 만들 때 말 그대로 '기준'이 되는 모델이다.
위에서 AI가 '저 친구'보다는 잘했다고 말한 것처럼, 학습 및 최적화를 거친 모델이라면 최소한 기준 모델보다는 성능이 좋아야 한다.
기준 모델은 무조건 이렇게 정해야 한다는 규칙은 없다.
다만 가장 간단하면서 흔하게 정해지는 유형은 다음과 같다.
- 회귀 문제 : 타겟의 평균값 (또는 중앙값)
- 분류 문제 : 타겟의 값 중 가장 많은 것 (타겟의 최빈 클래스)
- 시계열 문제 : 이전 타임스탬프의 값
앞서 말했듯이 꼭 이를 기준 모델로 삼을 필요는 없다.
회귀 문제라면 선형 회귀를, 분류 문제라면 로지스틱 회귀를 기준 모델로 정할 수도 있다.
즉, 정하는 사람 마음이다.
기준 모델은 어떻게 쓰는거지?
기준 모델이 무엇인지 알았으니 구체적인 사용 예시를 코드와 함께 살펴보겠다.
여기서는 회귀와 분류 문제 각각에서 기준 모델을 설정 후, 이를 실제로 만들 모델(이하 실제 모델)과 어떤 식으로 비교하는지 설명하겠다.
(코드에 대한 구체적인 설명은 아래 참고 자료에 포함된 Colab 링크를 보시면 확인 가능합니다.)
- 데이터 전처리 및 가공
# ! pip install category_encodersimport pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from category_encoders import TargetEncoder, OrdinalEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.compose import TransformedTargetRegressor
from sklearn.linear_model import RidgeCV, LogisticRegression
from sklearn.model_selection import train_test_split, RandomizedSearchCV
from sklearn.pipeline import make_pipeline
from sklearn.metrics import mean_absolute_error, r2_score, accuracy_score, f1_score, classification_report
from scipy.stats import randint, uniform# 자료 출처 : 서울 열린데이터 광장 - 서울특별시 부동산 실거래가 정보
# https://data.seoul.go.kr/dataList/OA-15548/S/1/datasetView.do
df = pd.read_csv('https://docs.google.com/uc?export=download&id=1WyeDe2Ry4ohJobcbnQJXHxFEAtcg-CC_', encoding='cp949')df = df[df['지번코드'].map(str).apply(len) == 19]
tmp_idx = df[df['층정보'] < 0]['층정보'].index
df.loc[tmp_idx, ['층정보']] = df[df['층정보'] < 0]['층정보'].mul(-1)
df = df[(df['건축년도'] != 0) & ~(df['건축년도'].isna())]
df['층정보'] = df['층정보'].fillna(2)
df = df[['지번코드', '건물면적', '층정보', '건물주용도코드', '물건금액', '건축년도']]df['연식'] = (2020 - df['건축년도']).astype(int)
df['주택규모'] = df['건물면적'].apply(lambda x: 'S' if x <= 60 else 'L' if x > 85 else 'M')
df['고가주택여부'] = df['물건금액'].apply(lambda x: 1 if x > 900000000 else 0)
df[['층정보', '건축년도']] = df[['층정보', '건축년도']].astype(int)
df.columns = ['addr_code', 'size', 'floor', 'type', 'price', 'built_year', 'years', 'size_grade', 'is_high_price']target = 'price'
df = df[df[target] < np.percentile(df[target], 95)]
df = df[df['size'] < np.percentile(df['size'], 95)]
df = df[df['years'] < np.percentile(df['years'], 95)]
df = df.reset_index(drop=True)- 기준 모델 설정 및 평가
회귀 : 타겟의 평균값 (평가지표 : MAE)
분류 : 타겟의 최빈 클래스 비율 (평가지표 : 정확도)
# 기준 모델(회귀) : 타겟(price)의 평균값
baseline = df.price.mean()
baseline470946234.08997595
# 기준 성능(회귀) - MAE
errors = baseline - df.price
baseline_mae = errors.abs().mean()
print(f'Baseline MAE: {baseline_mae:,.0f}')Baseline MAE: 254,535,177
# 기준 모델(분류) : 타겟(is_high_price)의 최빈 클래스 비율
sns.countplot(x=df.is_high_price);
df.is_high_price.value_counts(normalize=True)
# 기준 성능(분류) - 정확도 = 0.895
# 모든 예측값을 0으로 찍어도 정확도가 0.895가 나옴
# 따라서 실제 모델의 정확도는 0.895보다 높아야 유효0 0.895478
1 0.104522
Name: is_high_price, dtype: float64
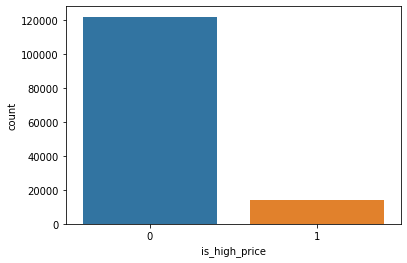
- 실제 모델 만들기 및 평가
# 물건가격 예측은 회귀, 고가주택 여부는 분류
# 회귀 : 릿지 회귀
# 분류 : 로지스틱 회귀
# 훈련 / 테스트 셋으로 분리
train, test = train_test_split(df, test_size=0.30, random_state=2)
train.shape, test.shape((95474, 9), (40918, 9))
# 특성과 타겟 분리하기
target_cl = 'is_high_price' # 분류 문제 타겟
targets = [target, target_cl]
features = train.drop(columns=targets).columns
X_train = train[features]
y_train = train[target]
y_train_cl = train[target_cl]
X_test = test[features]
y_test = test[target]
y_test_cl = test[target_cl]# 범주형 특성 인코딩을 위해 특성들을 구분
tge_col = ['addr_code', 'type'] # 범주 간의 순서가 없는 특성
ord_col = ['size_grade'] # 범주 간의 순서가 있는 특성(소/중/대)# 1. 회귀 - 릿지 회귀
alphas = [0, 0.001, 0.01, 0.1, 1]
pipe_ridge = make_pipeline(
TargetEncoder(cols=tge_col),
OrdinalEncoder(cols=ord_col),
RidgeCV(alphas=alphas, cv=5)
)
tt_ridge = TransformedTargetRegressor(regressor=pipe_ridge,
func=np.log1p, inverse_func=np.expm1)
tt_ridge.fit(X_train, y_train);
y_pred_ridge = tt_ridge.predict(X_test)
mae_ridge = mean_absolute_error(y_test, y_pred_ridge)
print(f'MAE: {mae_ridge:,.0f}')MAE: 86,647,593
# 2. 분류 - 로지스틱 회귀
# class weights 계산
# n_samples / (n_classes * np.bincount(y))
custom = len(y_train_cl)/(2*np.bincount(y_train_cl))
pipe_logis = make_pipeline(
TargetEncoder(cols=tge_col),
OrdinalEncoder(cols=ord_col),
StandardScaler(), # 각 특성별 스케일을 통일시켜줌
LogisticRegression(class_weight={False:custom[0],True:custom[1]}, random_state=2)
)
pipe_logis.fit(X_train, y_train_cl)
y_pred_logis = pipe_logis.predict(X_test)
accu_logis = accuracy_score(y_test_cl, y_pred_logis)
print(f'Accuracy Score: {accu_logis:,.3f}')Accuracy Score: 0.953
- 결론
- 회귀
- 기준 모델 MAE = 254,535,177
- 실제 모델 MAE = 86,647,593
- 분류
- 기준 모델 정확도 = 0.895
- 실제 모델 정확도 = 0.953
회귀, 분류 모두 실제 모델이 기준 모델보다 성능이 뛰어나므로 실제 모델을 '당장 버릴 필요는 없다'고 볼 수 있다.
- 주의할 점
당연한 말이지만, 기준 모델과 실제 모델의 성능 비교 시 동일한 평가지표를 기준으로 하여 비교해야 한다.
나의 경우, 타겟의 최빈 클래스 비율을 실제 모델의 F1 Score와 비교를 하는 실수를 저질렀는데, 둘 모두 0에서 1 사이의 값으로 표현이 되다 보니 작업을 하는 도중 혼동이 있었다.
따라서 비교 대상이 무엇인지 명확하게 한 후에 비교를 진행해야 할 것이다.
또한 만든 모델이 기준 모델보다 성능이 좋다고 해서 항상 사용 가능하다고 볼 수는 없다.
위에서 '당장 버릴 필요는 없다'고 표현한 이유도, 당장은 기준 모델보다 성능이 좋아도 이 모델을 실전에 투입하는 것은 다른 문제이기 때문이다.
예를 들어 기준 모델의 정확도가 0.3이고 실제 모델은 0.31이 나왔다면 이를 바로 실전에서 쓸 수 있을까?
상황에 따라 다르겠지만, 아무래도 바로 쓰기에는 망설여질 것이다.
<참고 자료>
- baseline - Cambridge English Dictionary
- baseline - Merriam-Webster
- Always start with a stupid model, no exceptions. - insightdatascience.com
- How To Get Baseline Results And Why They Matter - Machine Learning Mastery
- What does "baseline" mean in the context of machine learning? - StackExchange
- Baselines - ML@CMU
- 딥러닝에서 바닐라 모델(Vanilla Model)과 베이스라인 모델(Baseline Model) [설명/요약/정리] - 만렙개발자