데이터베이스 정규화(Database Normalization)
데이터베이스 정규화란?
관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화(Normalization)라고 한다.
데이터베이스 정규화의 목표는 이상이 있는 관계를 재구성하여 작고 잘 조직된 관계를 생성하는 것에 있다. 일반적으로 정규화란 크고, 제대로 조직되지 않은 테이블들과 관계들을 작고 잘 조직된 테이블과 관계들로 나누는 것을 포함한다.
정규화의 목적은 하나의 테이블에서의 데이터의 삽입, 삭제, 변경이 정의된 관계들로 인하여 데이터베이스의 나머지 부분들로 전파되게 하는 것이다.
- 위키백과 (데이터베이스 정규화)
잔뜩 어질러져 있는 방을 상상해보자.
정리되지 않은 침대와 책상, 방 곳곳에 널부러져 있는 다양한 옷과 양말들, 쓰러진 행거, 어제 밤에 다 먹고서 치워 놓지 않은 비어 있는 치킨 박스와 사이다 페트병 등등...
이런 와중에 옷이나 가구를 새로 사서 방에 두려고 한다. 과연 순순히 될까?
그 전에 방 정리부터 해야 뭘 사서 들여놓던가 할 수 있을 것이다.
데이터베이스도 이와 같다.
데이터베이스 정규화란 잔뜩 어질러진 방과 같은 데이터베이스의 내부를 일정한 규칙을 통해 깔끔하게 정리정돈하는 것이다.
이렇게 정리정돈을 함으로써 데이터베이스에서 중복되는 데이터를 줄이고, 새로운 데이터의 삽입 / 갱신 / 삭제가 잘못될 위험을 없앤다(이상 현상 제거).
또한 데이터베이스의 구조를 확장할 때에도 기존의 구조를 거의 건드리지 않고 할 수 있다.
(여기서의 데이터베이스는 관계형 데이터베이스를 말한다.)
이상 현상이란?
데이터베이스의 정규화가 제대로 되지 않으면 데이터를 삽입 / 갱신 / 삭제할 때 예상과 다른 결과를 얻을 수도 있다. 이를 이상 현상(Anormaly)이라고 한다.
1) 삽입 이상 (Insert Anormaly)
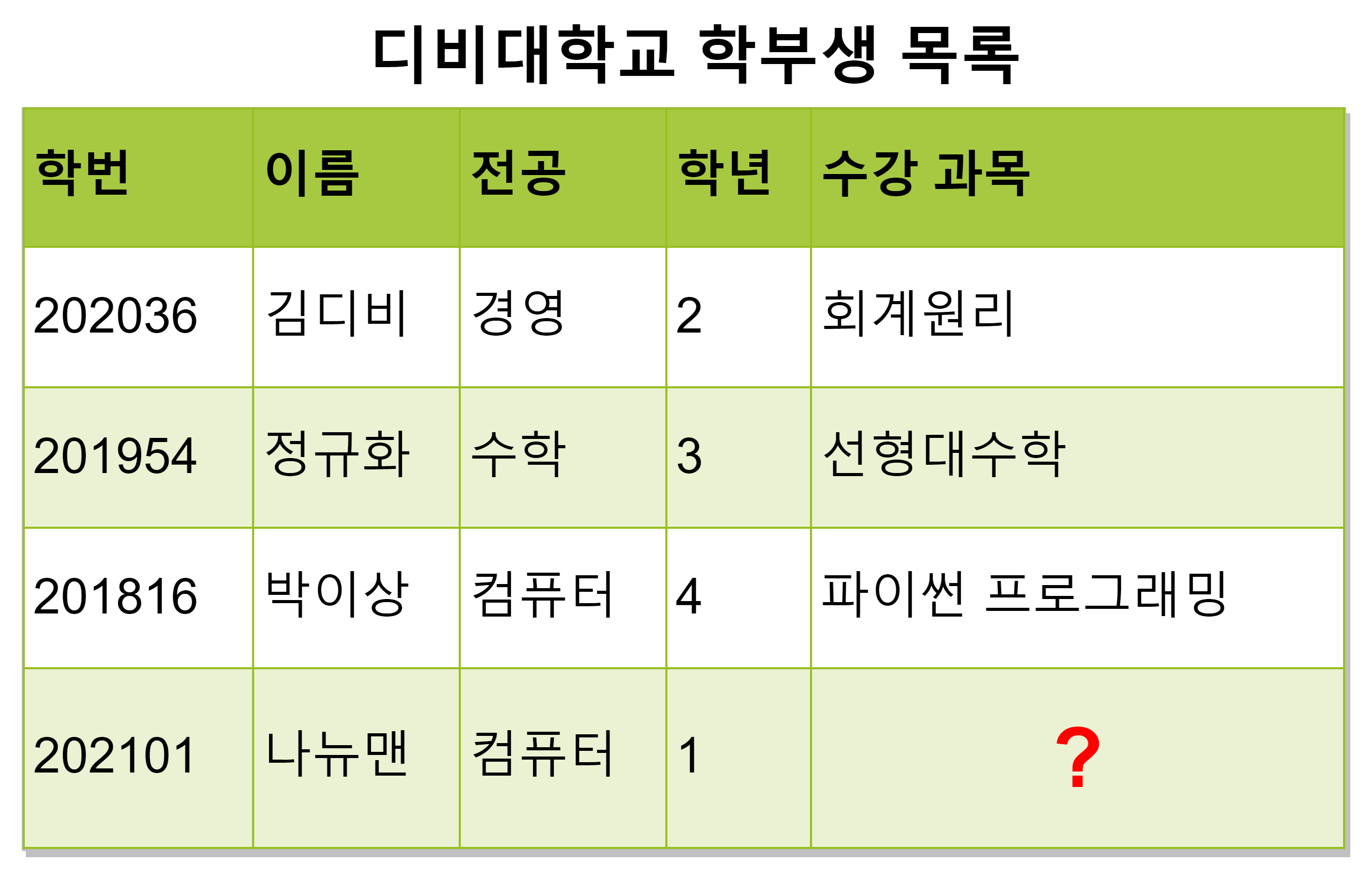
대학교 학부생 목록에 신입생 '나뉴맨'의 데이터를 추가하려고 한다. 그러나 아직 수강 신청을 하지 않아 수강 과목 정보가 없다.
이러면 이 신입생의 수강 과목 값을 null로 하지 않는 이상 데이터를 추가할 수가 없다.
이런 경우를 삽입 이상이라고 한다.
2) 갱신 이상 (Update Anormaly)
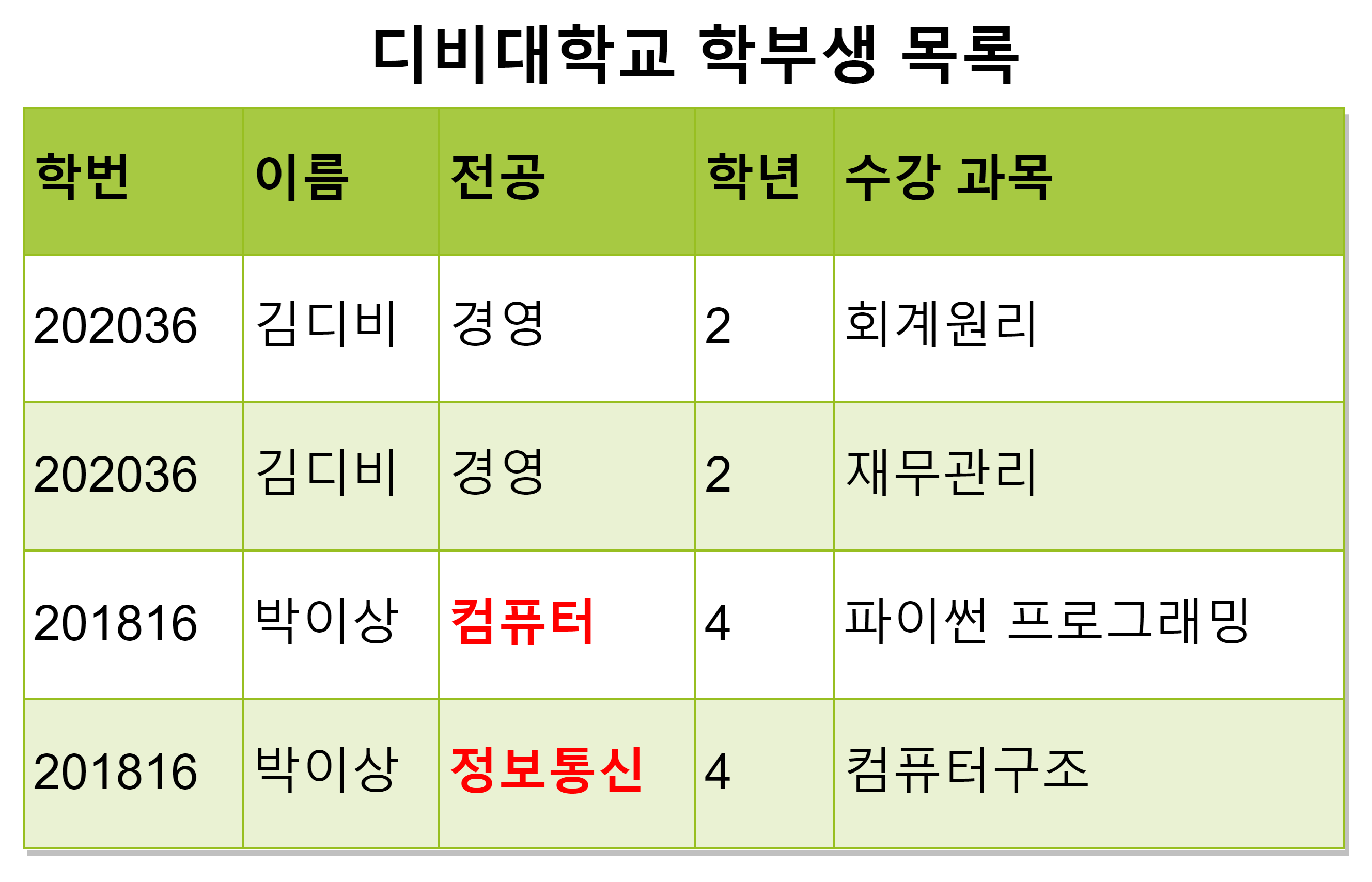
학부생 중 '박이상'의 전공이 컴퓨터에서 정보통신으로 변경되었다. 따라서 '박이상'의 전공 값을 갱신하였다.
'박이상'의 레코드가 여러 개 있기 때문에, '박이상'의 전공 정보를 변경하려면 여러 개의 레코드가 함께 바뀌어야 했다.
그러나 갱신 처리 도중에 문제가 생겨 일부 레코드만 갱신이 되었다. 이로 인해 '박이상'의 전공이 무엇인지 정확히 알 수 없게 되었다.
이런 경우를 갱신 이상이라고 한다.
3) 삭제 이상 (Delete Anormaly)

'김디비'가 회계원리가 어려워서 수강 취소를 신청했다. 그래서 '김디비'의 수강 과목이 회계원리인 데이터를 삭제하려고 한다.
그런데 이렇게 하려고 보니 '김디비'의 레코드를 통째로 삭제하게 생겼다. 이러면 '김디비' 학생이 우리 학교에서 영영 사라지는데...?
이런 경우를 삭제 이상이라고 한다.
데이터베이스 정규화는 어떻게 하지?
데이터베이스 정규화는 정규화되는 정도에 따라 제 1 정규형(1NF, the first Normal Form)부터 제 6 정규형과 함께 EKNF, BCNF, ETNF, DKNF가 있다.
보통 제 3 정규형가지 만족하는 데이터베이스를 "정규화 되었다(normalized)"고 말한다.
따라서 여기서는 제 3 정규형까지만 다루겠다.
1) 제 1 정규형

제 1 정규형에서 데이터 테이블에 있는 레코드는 각각의 컬럼마다 단 한 개의 값만 가져야 한다.
'내 친구 목록' 테이블에서 '존'은 취미 2개가 함께 써있다. 이를 분리하여 아래와 같이 별도의 레코드로 만들어야 한다.

2) 제 2 정규형
제 2 정규형은 제 1 정규형을 만족하는 테이블의 컬럼들 간에 부분 함수적 종속이 없어야 한다(달리 말하면 완전 함수적 종속을 만족해야 한다).
함수적 종속이란?
수학의 함수에서 $x$에 의해 $y$가 결정이 되듯이, 데이터베이스에서 어떤 관계의 부분 집합 X와 Y가 있고, X에 의해 Y가 결정될 수 있으면 이때 Y는 X에 함수적 종속이라고 한다.
여기서 X 자체만으로 Y가 결정되면 완전 함수적 종속이라고 하고, X 내의 또 다른 부분 집합으로도 Y가 결정될 수 있으면 부분 함수적 종속이라고 한다.
제 1 정규형을 만족한 '내 친구 목록' 테이블을 보면 각 레코드는 {이름, 취미}를 통해 구분이 된다.
그런데 나이, 집 주소, 거주 국가, 거주 도시는 {이름}만 갖고도 정해질 수 있다. {이름, 취미}가 아닌 {이름}만으로도 이 속성들이 결정되므로 부분 함수적 종속이 있다.
이를 제거하기 위해 아래와 같이 테이블을 분리한다.

3) 제 3 정규형
제 3 정규형은 제 2 정규형을 만족하는 테이블의 컬럼들 간에 이행적 함수 종속이 없어야 한다.
이행적 함수 종속이란, A이면 B이고, B이면 C일 때, A는 C인 관계(A->B, B->C, A->C)인 관계가 성립하는 것이다.
즉, 데이터베이스 테이블에서 기본 키가 아닌 다른 컬럼이 또 다른 컬럼을 결정하는 경우를 말한다.
A :인간은 동물이다.
B : 동물은 죽는다.
C : 인간은 죽는다.
제 2 정규형을 만족하는 '내 친구 목록' 테이블을 보면 {이름}을 통해 집 주소를 알 수 있다.
그리고 {집 주소}를 통해 거주 국가와 거주 도시를 알 수 있다.
따라서 이행적 함수 종속이 존재하므로 이 테이블을 아래와 같이 분리한다.

역정규화(Denormalization)
역정규화는 정규화의 단계를 낮추는 것이다.
정규화를 하면 할수록 테이블이 세부적으로 나누어진다. 이를 통해 데이터의 중복이 감소하고, 각 테이블의 의미도 보다 뚜렷해지는 등의 장점이 있다.
그 대신 세분화된 테이블로 인해 한 테이블 내에서 필요한 데이터를 한 번에 불러오기가 힘들어진다. 이로 인해 JOIN 등을 통해 여러 테이블로부터 필요한 데이터를 불러와야 하는데, 이는 쿼리의 요청 처리 시간이 늘어나는 문제가 있다.
이런 이유로 정규화의 단계를 낮춰 약간의 데이터 중복을 허용함으로써 JOIN과 같이 처리 시간을 늘리는 쿼리의 사용 횟수를 줄인다. 그 결과 전체적인 시스템의 속도가 향상되는데, 이것이 역정규화의 목적이다.
※ 주의 : 역정규화(denormalization)는 비정규화(unnormalized form)와 다른 것이다. 역정규화를 위해서는 먼저 정규화가 되어야 한다.
<참고 자료>
- 데이터베이스 정규화 - 위키백과
- Database normalization - Wikipedia
- Functional dependency - Wikipedia
- 데이터베이스 정규화 1NF, 2NF, 3NF, BCNF
- 정규화, 어렵지 않게 시작하기 - pageseo
- [Database] 정규화(Normalization) 쉽게 이해하기 - MangKyu's Diary
- [DB 이론] 데이터베이스 정규화란? (이상 문제, 함수적 종속, 정규화 과정) - Nirsa
- Normalization in DBMS: 1NF, 2NF, 3NF and BCNF in Database - BeginnersBook
- 역정규화
'Database > Knowledge' 카테고리의 다른 글
| [DB] 데이터베이스 언어 (Database Language) (0) | 2021.11.25 |
|---|---|
| [DB] 데이터베이스 스키마(Database Schema) (feat. 데이터베이스 사상(Database Mapping)) (0) | 2021.11.24 |
| [DB] 데이터베이스 트랜잭션(Database Transaction) (0) | 2021.11.21 |
| [DB] 데이터베이스 관계(Database Relationships) (0) | 2021.11.18 |